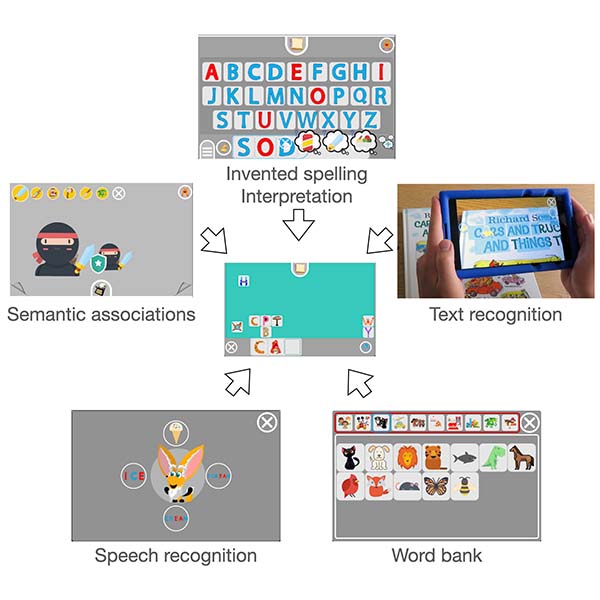
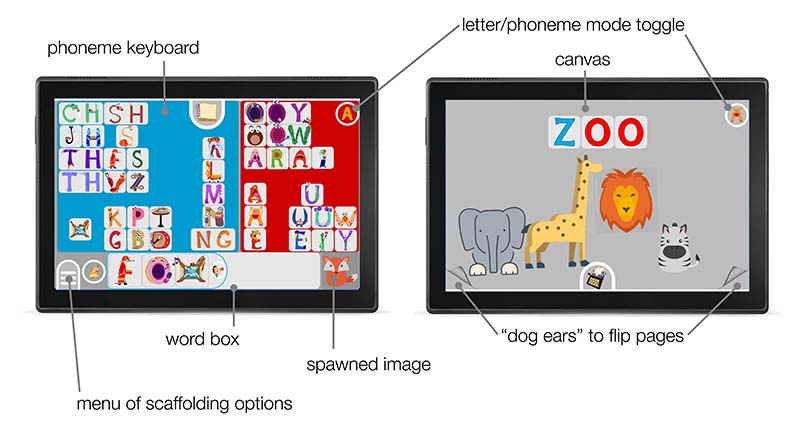
Help the player come up with ideas. It was fulfilled particularly well by the association network. In the ninja example, the child appeared to ran out of ideas and resorted to the associations. She went through a long sequence starting with SWORD: SWORD -> WARRIOR -> HERO -> BATMAN -> DRAGON -> UNICORN -> CENTAUR -> GOBLIN -> WARRIOR -> HERO -> SOLDIER -> PRISONER - before she stumbled upon PRISONER. That gave her a new idea on what to build, one she was very excited about.
Be a fallback option. The "high-tech" modes of input, such as speech recognition or text recognition, were far from being perfectly reliable. On occasions when they childen could resort to using word bank, which was simple and robust, while still having plenty of interesting words to build.
Speech recognition was valuable
We were originally concerned that due to low quality of existing ASR systems on children's voices, the speech recognition input would be unusable. But children ended up using it successfully - partially because of the decision to show multiple recognition candidates, partially because of their own persistence. When the ASR failed to understand them, they patiently repeated their request for up to 6 times. This persistence also indirectly indicates the value of the system to them.
Two interesting things were observed with respect to ASR usage. First, children tended to speak to the system in sentences, e.g. "Mr. Fox, please give me a GORILLA". Second, they treated Mr. Fox (the avatar of the system) as a living character, talking to him politely, asking him to do things (“Mr. Fox, what time it is?”, “Mr. Fox, finish off (turn off) the tablet!”), asking us about his abilities ("Can he fly?"), encouraging him when ASR failed to deliver correct result (“Oh no! Mr. Fox, we need you! Mr. Fox, spell FIRE!”) and appreciating his work when the result was correct ("Mr. Fox, you busted it out!" (apparently in the sense "produced"), "Fox, I love you"). These observations may be useful in designing interfaces for open-ended speech interaction for children.
Invented spelling interpretation was hard to use
We only saw one child who consistently and purposefully built words using this method. For example, she used SR to make STAR, HR - to make CHAIR (note how she used the name of the letter H - [eɪtʃ] – to represent the sound [tʃ]). Other children typically just randomly arranged blocks in the input box until by chance they stumbled upon an output that they liked.
Here is some speculation as to why it might have been the case. First, it appears that many children didn't have sufficient phonological skills to identify the needed sounds. For example, during the demo period, a child couldn't identify the initial sound in BATMAN, saying "BATMAN starts with BATMAN". When asked to identify the last sound in a BOAT, he answered with the first sound ([b]), even when asked to try again. Second, children rarely removed blocks from the word box, even when they tried out multiple blocks in search for the correct sound. For instance, while trying to spell BOMB, a child first represented the sound [ɑ] as A, then O, and ended with BAO. Such scenarios led the interpreter astray. Finally, children occasionally put suitable blocks, but in the wrong order. The knowledge of spelling direction is not always firmly established at this age.
Given the proliferation of invented spellings in our studies with older children, it is possible that this input method would work much better for older ages.
Text recognition was problematic
Though children were excited about using text recognition, it was often associated with frustration, confusion and distraction. First, there were various issues with picking up words: (1) children holding the camera sideways relative to the text, or holding it too close to focus, or putting the tablet on top of the text; (2) players having a poor grip and shaking the tablet, which disrupted the camera's focus; (3) reflective surfaces producing glare; (4) child-oriented materials often containing highly stylized and decorative fonts; (5) words written by teachers on the board being underlined or smudged.
Second, children eagerly spelled the results of OCR errors, such as: CALE (for CUTE), DRAGO (for DRAGON), RZONT, FADER, LOORM, HEELS (for WHEELS), SOO, ODA. Since pre-literate children don't know what words actually "say", that might lead to confusion.
Finally, OCR was quite distracting for some. The most notable issue was "picture-taking". The user interface of OCR had a freeze button, intended to allow children to freeze the picture, put down the bulky tablet and pick the words from the snapshot. However, some children used this button to take portraits of their friends. Another unintended activity was to use the interface like camera-obscura to look around through it. Some children were also interested in just pointing at words around the classroom, waiting until they turn green and moving on. Still another activity was to explore the texts via hearing the words, but never attempting to spell them. While the last activity might have some literacy value, it is disconnected from the primary purpose of the system. These distractions were likely the reason why the week OCR was introduced, the number of spelled words per child fell nearly 20% compared to the previous week, and never returned to the level of that week.